When a CronJob Breaks Home Assistant: Debugging K3s kube-router NetworkPolicy REJECT Gaps

TL;DR: A Home Assistant button that talks to a tiny in-cluster REST bridge started failing intermittently on my small K3s cluster. After I ruled out DNS, the application, VXLAN, a recent Linux bridge change, and several plausible kernel theories, the cause turned out to be a reconciliation gap in K3s’s embedded kube-router NetworkPolicy controller: during observed policy reconciles, a selected pod’s iptables path could briefly lose the expected allow mark, and traffic falls through to a terminal REJECT. The lesson is that iptables-based NetworkPolicy needs explicit observability, and chatty workloads do not belong under strict egress in a churn-heavy cluster.
Disclaimer. This is a locally confirmed failure mode on K3s v1.34.4 with the embedded kube-router NetworkPolicy controller, observed under heavy pod churn. It is consistent with how kube-router updates iptables, but I have not reproduced it upstream. The conclusions apply to similar K3s setups; I make no claim about kube-router in general.
The symptom
A Home Assistant button that calls a small REST bridge, vm-waker, started failing intermittently.
The visible Home Assistant errors looked like normal application noise at first:
Network unreachable
MDNS lookup failed
Could not contact DNS serversBut the same kind of failure also appeared against unrelated targets:
traccar.automation.svc
www.googleapis.com
met.noThat was the first clue: this was probably not a vm-waker problem. It looked like a short-lived outbound networking failure from the Home Assistant pod itself.
My cluster is a small K3s homelab:
K3s: v1.34.4
CNI: flannel VXLAN
NetworkPolicy: K3s embedded kube-router NetworkPolicy controller
Home Assistant node: node1
Home Assistant pod CIDR: 10.42.0.0/24
vm-waker node: node2
vm-waker pod CIDR: 10.42.1.0/24There had also been a recent networking change: the physical NIC on node2 had been moved under a Linux bridge, br0, to give a Windows/libvirt VM LAN access.
br0 was my first suspect. It was the wrong one.
The first misleading signal: bridge drops
Node exporter showed live drops on br0:
node_network_receive_drop_total{device="br0"} rising around 1 packet/secThe existing Grafana dashboard only showed bandwidth. It did not show drops, errors, or conntrack usage. So this signal would never have surfaced unless I went digging in the raw node exporter metrics.
That is a dashboard gap worth fixing, but it did not explain the actual Home Assistant failure.
The important observation came later: the br0 drops were steady background noise and did not correlate with the Home Assistant failure bursts.
Reproducing the failure
From inside the Home Assistant pod, calls to the vm-waker pod IP failed intermittently. The first reproduction appeared to show a difference between blocking and non-blocking sockets:
blocking socket.connect(): OK
asyncio / aiohttp: ENETUNREACH
explicit bind((podIP, 0)): OKMy first theory was a source-selection, route-cache, or TCP metrics issue.
Then the picture changed. During a later burst, all socket types failed together. Between bursts, all socket types worked.
A 60-second probe made the pattern obvious:
1 connection attempt every 0.5s
120 attempts total
73 OK
47 FAIL
failure rate: ~39%The failures were clustered. For several seconds everything failed instantly, then everything worked again.
That ruled out a lot:
Not DNS: raw pod IPs failed too
Not vm-waker: unrelated targets failed too
Not VXLAN only: same-node traffic also failed
Not br0 only: same-node traffic never touched node2's br0
Not tcp_metrics: the HA pod netns had zero tcp_metrics entries
Not resource exhaustion: HA CPU, memory, process count and sockets looked normalWhatever it was, it stayed local to the node, came in bursts, and failed instantly instead of timing out.
That points to one place: the node firewall path.
The real clue: KUBE-ROUTER reject counters
K3s includes an embedded NetworkPolicy controller based on kube-router’s netpol controller library. kube-router implements Kubernetes NetworkPolicy using iptables, ipset and conntrack.
Selected pods therefore get iptables chains like this:
KUBE-POD-FW-...
KUBE-NWPLCY-...
KUBE-ROUTER-INPUT
KUBE-ROUTER-OUTPUT
KUBE-ROUTER-FORWARDDuring a failure burst, iptables counters showed Home Assistant packets hitting REJECT.
One sample showed this kind of rule path:
-A KUBE-ROUTER-OUTPUT -d 10.42.0.171/32 \
-m comment --comment "rule to jump traffic destined to POD name:homeassistant..." \
-j KUBE-POD-FW-TTWOULJ7E7NSCXOJ
-A KUBE-ROUTER-OUTPUT -s 10.42.0.171/32 \
-m comment --comment "rule to jump traffic from POD name:homeassistant..." \
-j KUBE-POD-FW-TTWOULJ7E7NSCXOJInside the Home Assistant pod firewall chain, packets are supposed to be matched by a NetworkPolicy chain and marked as allowed. If they are not marked, the chain eventually rejects them:
-A KUBE-POD-FW-TTWOULJ7E7NSCXOJ \
-m mark ! --mark 0x10000/0x10000 \
-j REJECT --reject-with icmp-port-unreachableThen came the real finding: the referenced NetworkPolicy chain appeared and disappeared during reconciliation:
KUBE-NWPLCY-NKAMHMAG27XZ7RD7 t=339:0 t=340:1At one timestamp the chain was missing. One second later it existed again.
At the same time, other KUBE-NWPLCY-* chains were being deleted and recreated.
During one observed second, the Home Assistant pod saw:
+59 REJECTsThat matched the application symptoms exactly.
What was happening
The failure sequence looked like this:
A pod starts/stops, or an EndpointSlice changes
↓
kube-router NetworkPolicy controller reconciles policy state
↓
KUBE-NWPLCY-* chains are recreated / swapped
↓
Home Assistant traffic enters its KUBE-POD-FW-* chain
↓
The expected allow chain is absent or not populated yet
↓
The packet does not receive the allow mark
↓
The default rule rejects unmarked traffic
↓
connect() fails immediately with ECONNREFUSED / ENETUNREACHThe distinction between loss and rejection explains the instant errors. Packet loss leads to timeouts and retries at the TCP level. A local REJECT makes the kernel return an error to the application immediately. Home Assistant was getting the second kind.
Why CronJobs made it worse
The cluster had several frequent CronJobs:
infra/home-ip-updater every 5 minutes
monitoring/cloudfront-to-loki every 10 minutes
monitoring/agilepoker-to-loki every 15 minutesTogether, these generated around 22 pod create/delete cycles per hour.
Suspending just these three CronJobs reduced the Home Assistant failure rate:
Before: 47/120 failures, around 39%
After: 15/66 failures, around 23%That did not eliminate the issue, but it showed pod churn was a significant trigger in this cluster.
The remaining failures likely came from other reconciliation triggers:
- other pod or EndpointSlice changes
- completed job cleanup
- controller periodic resync
- the cost of recomputing a large number of policies
The cluster had around 130 NetworkPolicies, including 71 in one namespace and 18 in the automation namespace. For how a small cluster accumulates that many policies in the first place, see I Hacked My Own Web App on Kubernetes on genioct.be.
With iptables-based policy enforcement, every reconciliation becomes more expensive as the number of policy-generated chains grows.
Confirming the scope
Only one NetworkPolicy selected the Home Assistant pod: the homeassistant policy itself.
There was no namespace-wide podSelector: {} policy accidentally selecting it.
That gave a clean experimental lever:
- Variant A: delete the Home Assistant NetworkPolicy entirely
- Variant B: keep ingress restrictions but allow all egress
Variant B is the more interesting test:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: homeassistant
namespace: automation
spec:
podSelector:
matchLabels:
app: homeassistant
policyTypes:
- Ingress
- Egress
ingress:
# keep existing ingress rules here
egress:
- {}If Variant B is clean, strict HA egress policy was too fragile.
If Variant B still fails, simply being selected by kube-router’s pod firewall path is enough to expose the pod to the reconciliation gap.
In that case, the workaround is to remove Home Assistant from NetworkPolicy selection entirely or move it to a policy-free namespace.
Commands that proved it
These were the most useful commands.
Check whether the pod has a kube-router firewall chain:
HA_POD=$(kubectl -n automation get pod -l app=homeassistant -o jsonpath='{.items[0].metadata.name}')
HA_IP=$(kubectl -n automation get pod "$HA_POD" -o jsonpath='{.status.podIP}')
sudo iptables-save -c | grep "$HA_IP"
sudo iptables-save -c | grep "$HA_POD"Watch for REJECT counters:
watch -n 1 '
date
sudo iptables-save -c | egrep "KUBE-POD-FW|homeassistant|REJECT" | head -100
'Find which NetworkPolicies select the pod:
kubectl -n automation get pod "$HA_POD" --show-labels
kubectl -n automation get netpol -o yamlCount policies per namespace:
kubectl get netpol -A --no-headers \
| awk '{print $1}' \
| sort \
| uniq -c \
| sort -nrList frequent CronJobs:
kubectl get cronjob -ASuspend noisy CronJobs for a controlled test:
kubectl -n infra patch cronjob home-ip-updater \
-p '{"spec":{"suspend":true}}'
kubectl -n monitoring patch cronjob cloudfront-to-loki \
-p '{"spec":{"suspend":true}}'
kubectl -n monitoring patch cronjob agilepoker-to-loki \
-p '{"spec":{"suspend":true}}'Restore them afterwards:
kubectl -n infra patch cronjob home-ip-updater \
-p '{"spec":{"suspend":false}}'
kubectl -n monitoring patch cronjob cloudfront-to-loki \
-p '{"spec":{"suspend":false}}'
kubectl -n monitoring patch cronjob agilepoker-to-loki \
-p '{"spec":{"suspend":false}}'Minimal proof checklist
You know you are looking at this failure mode when all of these line up:
- Raw pod IP connections fail, so DNS is not the root cause.
- Failures return errors instantly instead of timing out.
iptables-save -cshowsKUBE-POD-FW-*REJECT counters increasing.- The affected pod is selected by a NetworkPolicy.
- The failure correlates with pod, EndpointSlice, or NetworkPolicy churn.
- Removing the pod from NetworkPolicy selection or relaxing egress changes the failure rate.
Immediate mitigations
The first mitigation was application-level retry logic around the Home Assistant rest_command.
It does not fix the root cause, but it is still correct engineering. Any local REST bridge used for automation should tolerate a short network blip.
The second mitigation is to make Home Assistant less fragile: keep the ingress restrictions, allow all egress.
Home Assistant is naturally a high-egress workload. It talks to local services, DNS, MQTT, cloud APIs, weather providers, mobile integrations, trackers and many devices. Strict egress policy gives limited value if it turns every policy reconciliation into a visible automation failure.
The third mitigation is to reduce churn:
- convert frequent CronJobs into long-running Deployments
- avoid creating Services for jobs that do not need inbound traffic
- reduce EndpointSlice churn
- consolidate duplicate NetworkPolicies
- remove unused policies
For example:
CronJob every 5 minutes
↓
Deployment with one replica
↓
internal sleep loop
↓
no pod create/delete cycle every 5 minutesA sleep-loop Deployment is less elegant than a CronJob, but it avoids unnecessary control-plane and policy churn for very frequent background tasks.
The proper platform fix
The deeper lesson is that a pod starting or finishing should not interrupt network traffic for unrelated workloads.
If it does, the policy engine is the wrong fit for a policy-heavy or churn-heavy cluster.
For K3s, that means not relying on the embedded kube-router NetworkPolicy controller when the cluster has many NetworkPolicies and frequent pod churn.
The durable fix is to move NetworkPolicy enforcement to a CNI with an eBPF datapath: Cilium, or Calico with its eBPF dataplane.
Cilium, for example, uses an eBPF-based datapath and can also replace kube-proxy for Kubernetes service handling.
Swapping the CNI on a running cluster touches everything:
- disable flannel
- disable embedded K3s NetworkPolicy
- clean old kube-router iptables rules
- install the new CNI
- validate CoreDNS, Services, and ingress
- validate Longhorn/storage traffic
- validate Home Assistant integrations
- validate observability
K3s documentation explicitly notes that kube-router NetworkPolicy iptables rules are not automatically removed when disabling the controller; they must be cleaned manually on all nodes.
That warning alone is enough to treat this as a planned maintenance activity.
Monitoring gaps to fix
The original dashboard showed Mbps but not drops, errors, conntrack or policy rejects.
Add at least:
sum by (instance, device) (
rate(node_network_receive_drop_total{device!~"lo|veth.*"}[5m])
)sum by (instance, device) (
rate(node_network_receive_errs_total{device!~"lo|veth.*"}[5m])
)100 * node_nf_conntrack_entries / node_nf_conntrack_entries_limitFor kube-router policy rejects, a small DaemonSet exporter can parse iptables-save -c and expose the per-pod REJECT counter to Prometheus:
iptables-save -c \
| awk '/KUBE-POD-FW/ && /REJECT/ {
gsub(/\[|\]/,"",$1);
split($1,a,":");
sum+=a[1]
}
END {
print "kube_router_pod_fw_reject_packets_total " sum+0
}'Then alert on any sustained reject rate:
rate(kube_router_pod_fw_reject_packets_total[2m]) > 5Once the exporter emits per-pod labels (node, namespace, pod), the same alert can be scoped with sum by (namespace, pod).
This would have made the problem visible much earlier.
Here is the resulting dashboard running in my cluster:
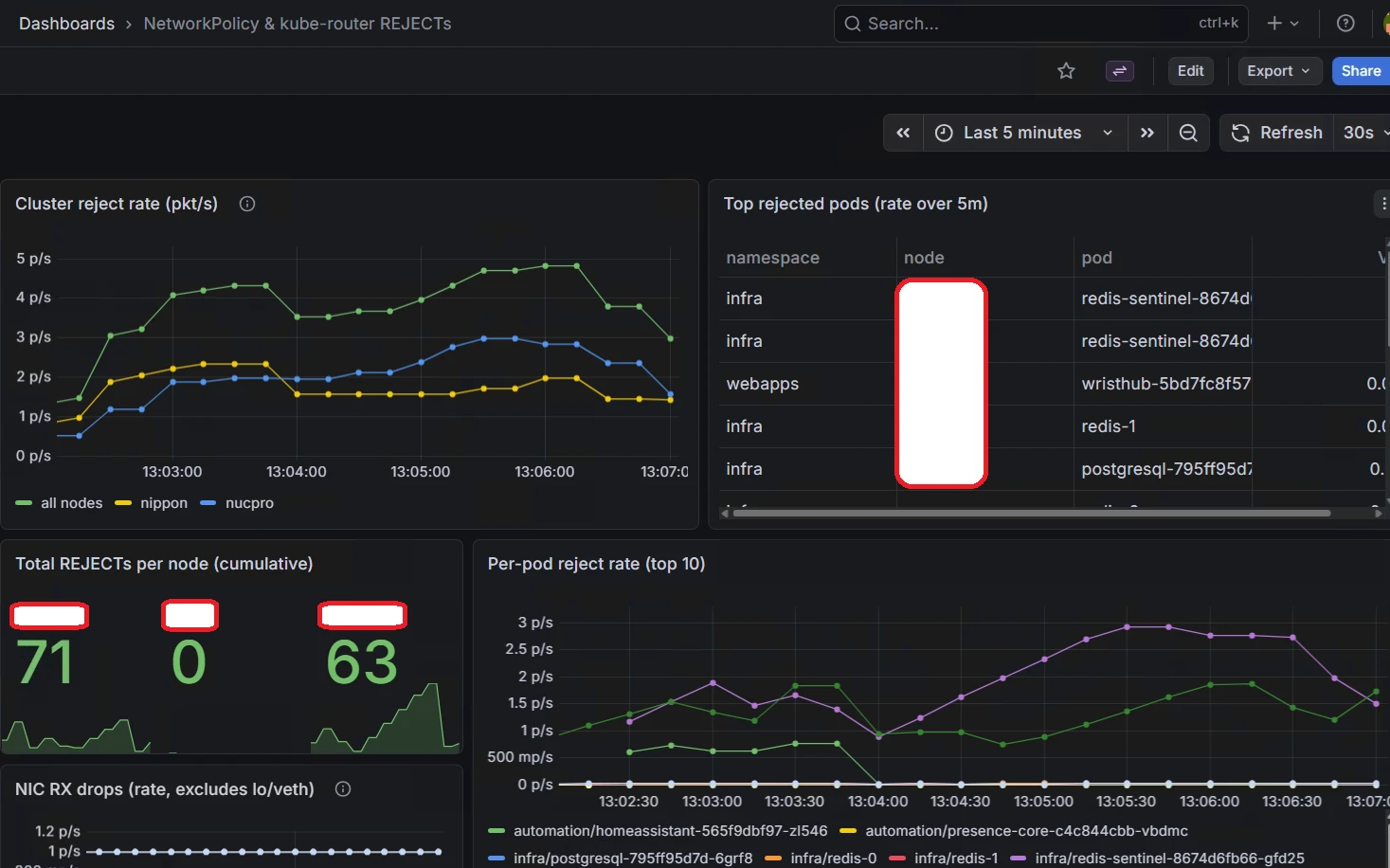
Home Assistant was the pod that surfaced the problem, but the dashboard immediately showed other selected pods (Redis Sentinel, PostgreSQL) collecting rejects too. The failure mode was cluster-wide; Home Assistant was simply the workload chatty enough to make it visible.
Final takeaways
Home Assistant, DNS, the REST bridge and VXLAN were all innocent. The cause was a transient local firewall reject during kube-router NetworkPolicy reconciliation.
The practical lessons:
- Testing against raw pod IPs separates DNS problems from datapath problems.
- Instant ENETUNREACH / ECONNREFUSED points to a local reject; packet loss shows up as timeouts.
- Check NetworkPolicy-selected pods in iptables as well as in Kubernetes YAML.
- Frequent CronJobs can create real datapath churn in iptables-based policy engines.
- Home Assistant is a poor candidate for strict egress policy in a small K3s homelab.
- Dashboards that only show bandwidth miss whole classes of network failure.
- If NetworkPolicy matters, use a datapath that does not rebuild active iptables chains under normal pod churn.
The short-term fix is to keep retries, relax Home Assistant egress, and reduce CronJob churn.
The long-term fix is to move NetworkPolicy enforcement away from K3s embedded kube-router and onto a CNI that enforces policy in eBPF.
References
- K3s networking services docs: embedded kube-router netpol controller,
--disable-network-policy, and manual cleanup ofKUBE-ROUTERiptables rules. - kube-router: How it works: NetworkPolicy implementation using iptables, ipset and conntrack.
- Kubernetes NetworkPolicy docs: egress/ingress isolation semantics and default-deny behavior.
- K3s issue #7244: kube-router iptables rules remaining after disabling NetworkPolicy.
- Cilium kube-proxy replacement docs: eBPF datapath positioning.