When Your Platform Team Can't Agree on the Stack
I facilitated an internal workshop for an enterprise platform team last year. The stated goal was educational: compare two infrastructure-as-code tools side by side, walk through principles, and settle on a direction. Simple enough.
Within 30 minutes, the session turned into something far more interesting than a tooling comparison. The team was split. One group wanted to explore a new tool that the rest of the organization was standardizing on. One engineer pushed back hard: “I’m not open to this. The solution we have is working. I don’t see the point.” The manager arrived late, walked into a room full of tension, and had to figure out how to move the team forward without breaking it.
The tooling comparison is a separate topic. What follows is about the human side: what happens when a technical disagreement in a platform team becomes a conflict about identity, sunk cost, and the fear of becoming a beginner again.
The Setup: A Team That Had Already Decided (or Had They?)
The team had built a working infrastructure platform over the course of a year. It was stable, tested, in production, deploying landing zones successfully. By any reasonable measure, a success.
But pain points had accumulated. Environment switching was manual. Dependency management between resources lived in pipeline logic instead of the code. Cross-resource-group deployments required orchestration workarounds. And the broader organization had standardized on a different tool, which meant the team spent energy defending their choice every time an enterprise architect asked questions.
Half the team saw these pain points as reasons to explore the organizational standard. The other half, particularly the engineer who had built the current solution, saw them as things to fix within the existing stack.
Both sides were right. That is what made it hard.
”I Wouldn’t Drop Something I’m Comfortable With to Become a Junior Again”
One sentence, spoken openly during the workshop, and it contained the entire conflict.
On the surface, two infrastructure tools. Underneath, professional identity. The engineer who resisted had invested months building the current solution. She knew its internals, its configuration model, its edge cases. Switching tools meant going from expert to beginner. That is not a trivial thing for someone whose professional reputation is tied to the system they built.
Every platform team facing a tooling migration has this dynamic. The people most qualified to evaluate the change are also the people with the most to lose from it. Their expertise becomes a liability in the new world. Their deep knowledge of the current system, the thing that makes them valuable today, becomes irrelevant if the team switches.
Until you recognize this, the conversation goes in circles. Feature comparisons and deployment scope arguments are a proxy for a question nobody wants to ask out loud: “Will I still matter if we change?”
Sunk Cost Is the Elephant in Every Migration Discussion
“We worked so many hours on it and it is working.” This is a legitimate statement. It is also textbook sunk cost reasoning.
Months of engineering effort went into the current platform: implementation, testing, hardening, production deployment. Proposing a switch meant implicitly saying that effort was wasted. Nobody wants to hear that. Nobody wants to believe that.
Better framing: not “we wasted our time” but “we learned what we need.” A working system teaches you requirements that no greenfield design can anticipate. The pain points the team identified (environment switching, dependency management, cross-scope deployments) were only visible because they had built and operated the first system.
But you have to name sunk cost explicitly in the conversation. Not as an accusation (“you’re being irrational”), but as a shared cognitive bias that the team can acknowledge together: “We all know it’s hard to consider replacing something we invested in. Let’s set that aside and evaluate based on what serves us going forward.”
In this workshop, nobody named it. The team danced around it for an hour. The resistance felt irrational to the explorers, and the exploration felt disrespectful to the builder. Both feelings were valid, and both were amplified by not naming the elephant.
The Manager Did Not Pick a Side
The team lead arrived midway through the session. By that point, the discussion had looped several times: same arguments, same pushback, no movement.
He did not pick a side. He did not say “use the new tool” or “keep what we have.” Instead, he asked three questions:
- “What would I need to defend this decision to the organization?”
- “How much time do you need to run a proper experiment?”
- “What does failure look like, so we know when to stop?”
Then he made a commitment: “You tell me how much time you need and I will make sure you have it. This is too important not to take seriously.”
Suddenly it was no longer my-tool-vs-your-tool. It was a structured experiment with a defined scope, timeline, and success criteria. Explorers got their proof of concept. Builder got a bounded commitment that would not derail ongoing delivery. Manager got a defensible decision process.
He did not need the right answer. He needed to create conditions for one to emerge, and the three questions did that.
The Timeboxed Experiment That Broke the Impasse
Here is what the team agreed on:
Current delivery continues. Nothing stops. Ongoing work, incoming requests, monitoring improvements: all as planned. Two engineers run a timeboxed proof of concept (two weeks, scoped to one specific landing zone slice) with the alternative tool, focused on the actual pain points: environment switching, dependency management, cross-scope deployments.
Before the experiment starts, the builder presents her improvement roadmap. A concrete plan for fixing the pain points within the current stack. Without this, the experiment feels like a foregone conclusion.
The team also predefined success criteria. If the proof of concept cannot achieve the defined goals in the timebox, the conclusion is “no-go.” Not a failure, a data point.
I now recommend this pattern for any “tool A vs. tool B” impasse. Don’t debate. Experiment. But scope and timebox it before you start, and agree on what success and failure look like.
Open-ended proof of concepts that drag on for months, accumulate enough code to create switching costs, and never formally conclude are the worst version of this. The team lead was explicit: “If we make a decision, we make a decision. I don’t want to reverse back in three weeks.”
What Actually Happened: The Dual-Track Model
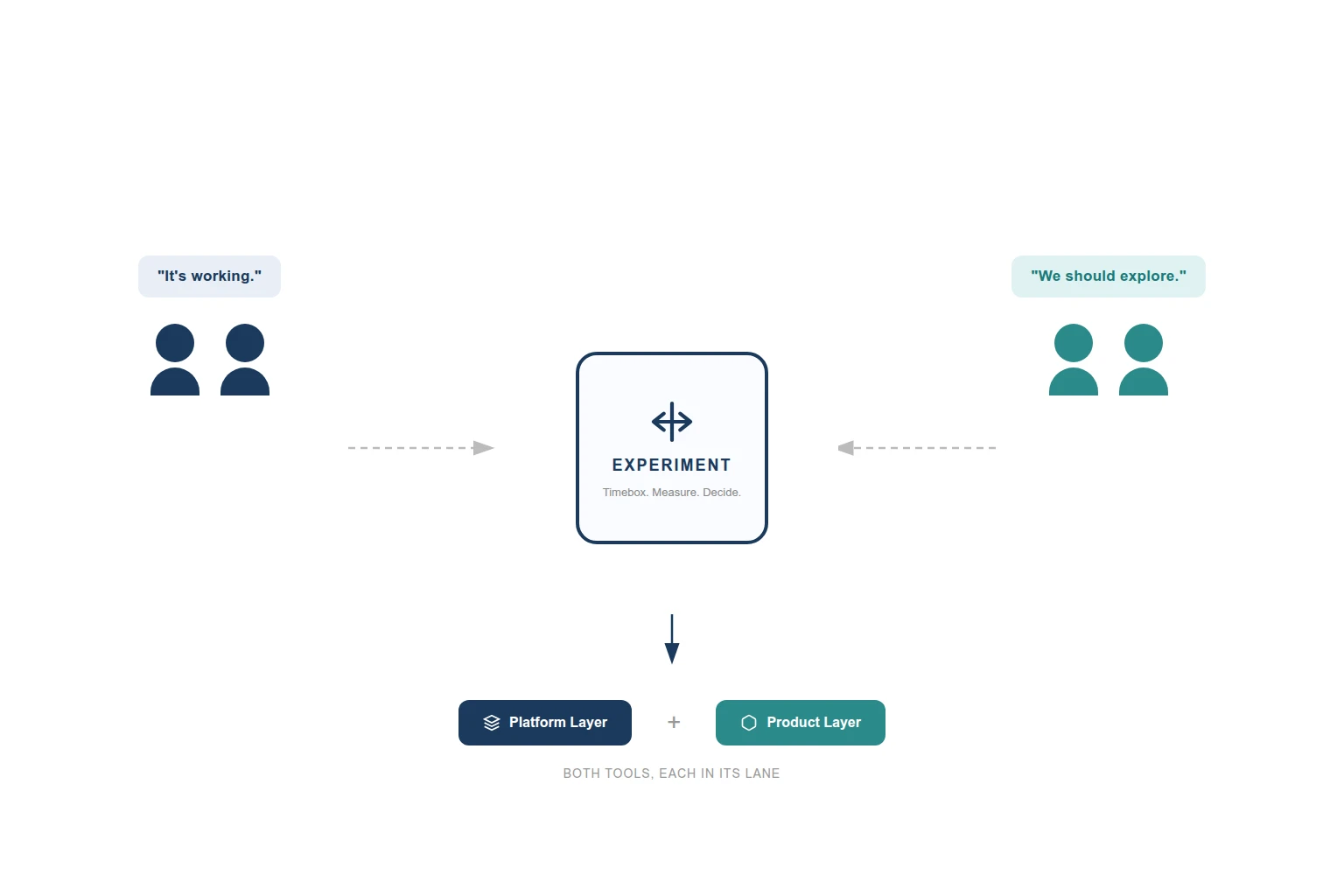
It worked. The proof of concept validated the alternative tool for product-level infrastructure. It also confirmed that the current platform was the right choice for landing zones, where stability and maturity mattered more than flexibility.
Both tools stayed, each in its lane. The existing tool kept the platform layer: landing zones, base networking, policy assignments, deployed once and rarely changed. The product layer moved to the new tool: application infrastructure, product-specific networking, anything deployed and modified frequently across environments.
Pipeline runs one, then the other. Clean boundary, no interference.
Nobody compromised. Nobody gave up something they cared about. Platform infrastructure and product infrastructure have different change frequencies, scope needs, and team ownership models. Using a single tool for both would have forced one side to fight the tool’s defaults.
The builder kept her central role, the explorers shipped real fixes, and the manager walked away with a decision he could defend.
What I Learned About Managing Technical Disagreements
The technical argument is almost never the real argument. People protect what they built and what they know. That drives more technical decisions than benchmark results ever will. Address the human layer first, or the technical conversation will loop forever.
When an experienced engineer says “I’m not open to this,” don’t route around them. Ask what they are seeing that you are not. Their prior experience with the alternative (in this case, a failed earlier attempt) is a data point that deserves genuine examination. Resistance is information.
If the person driving the discussion has a stake in the outcome, participants sense it. Either have someone without a preference facilitate, or be transparent about your position from the start. “I think we should explore X, and here is why” is more honest than framing a directional argument as an educational session. I learned this one the hard way.
Managers should create decision structure, not pick sides. Define the experiment, timebox it, set success criteria, commit to defending whatever the data shows.
And “both” is a valid answer. Real enterprises are messy. Sometimes two tools, each scoped to where they excel, is the pragmatic answer. Draw a clean boundary between them so the team does not maintain two solutions for the same problem.
One thing I underestimated: parallel work tracks require active management. Letting one group continue on the current stack while another experiments sounds clean. Without oversight, it creates factions. Check in regularly, share findings across tracks, and make sure the experiment’s outcome reaches everyone, not just the people who ran it.
The Uncomfortable Truth About Change Management in Platform Teams
Enterprise change management frameworks (ADKAR, Kotter, Prosci) work well for organizational-level transformations. They are too heavy for a five-person platform team debating IaC tooling. But the underlying principles still apply.
The workshop worked because I started with awareness: agreeing on pain points before discussing solutions. By the time tools were compared, everyone shared the same problem definition. Desire was harder. You cannot force an engineer to want to learn a new tool. You can create conditions where curiosity is rewarded and expertise is preserved, which the dual-track model did.
Where I fell short was ability. “You will all be juniors” is a fear that needs a concrete mitigation plan: pair programming, knowledge sharing sessions, realistic ramp-up timelines. I underinvested here. The builder’s participation in the experiment was minimal, which deepened the divide rather than bridging it.
The team lead’s insistence on a written decision with motivation turned out to be the single most useful intervention in the entire process. Reinforcement, in ADKAR terms. Document the decision, document the reasoning, and revisit it after six months.
You can always switch tools later. Rebuilding trust between engineers after a badly handled migration takes much longer.